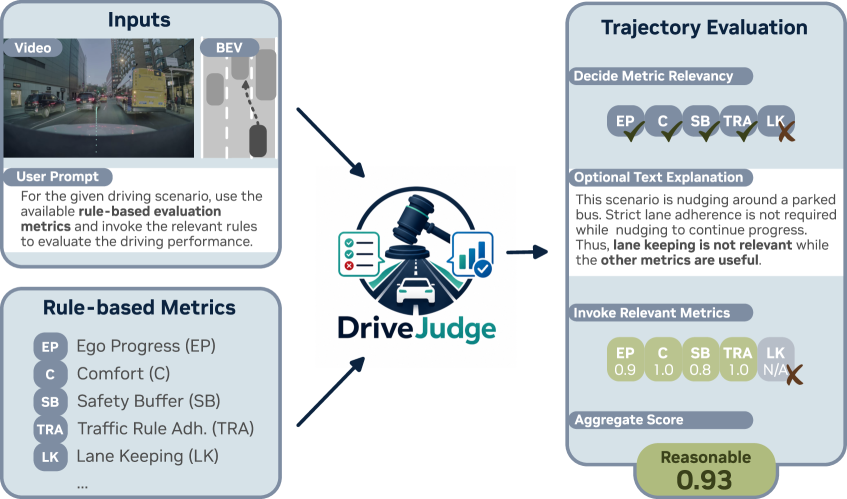
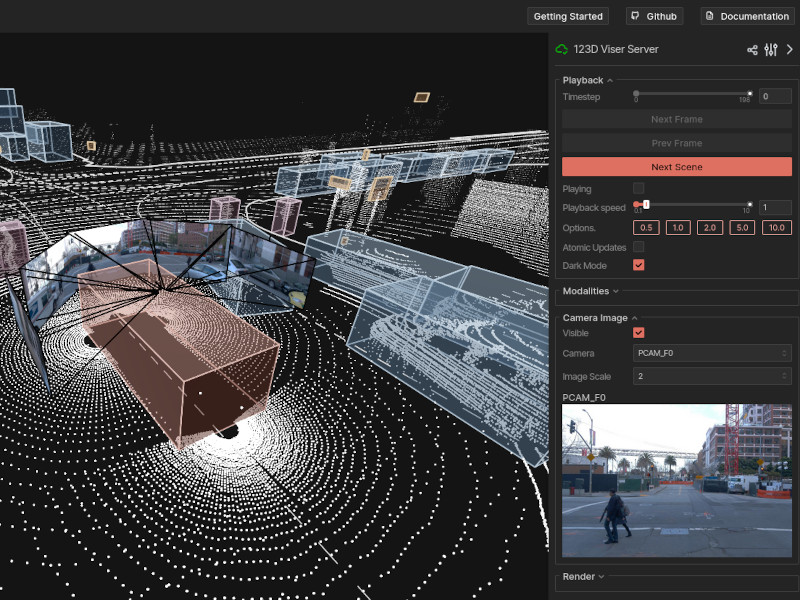
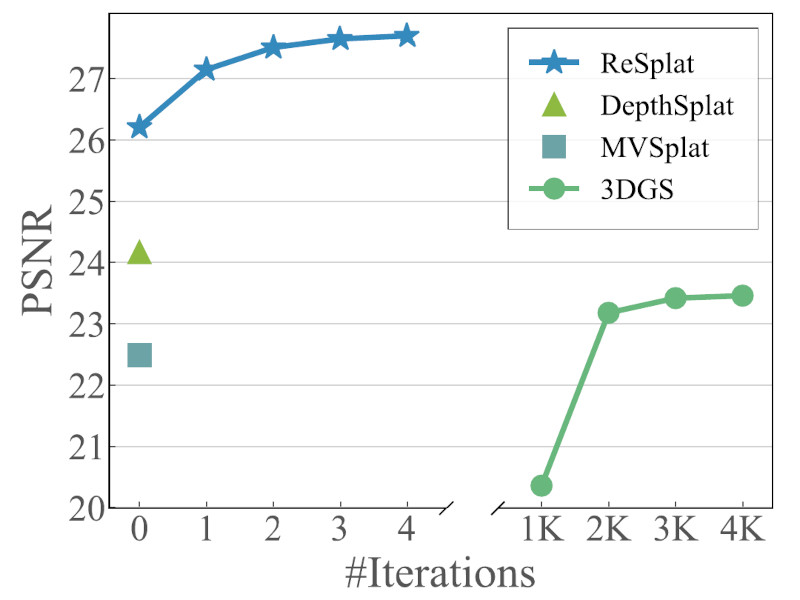
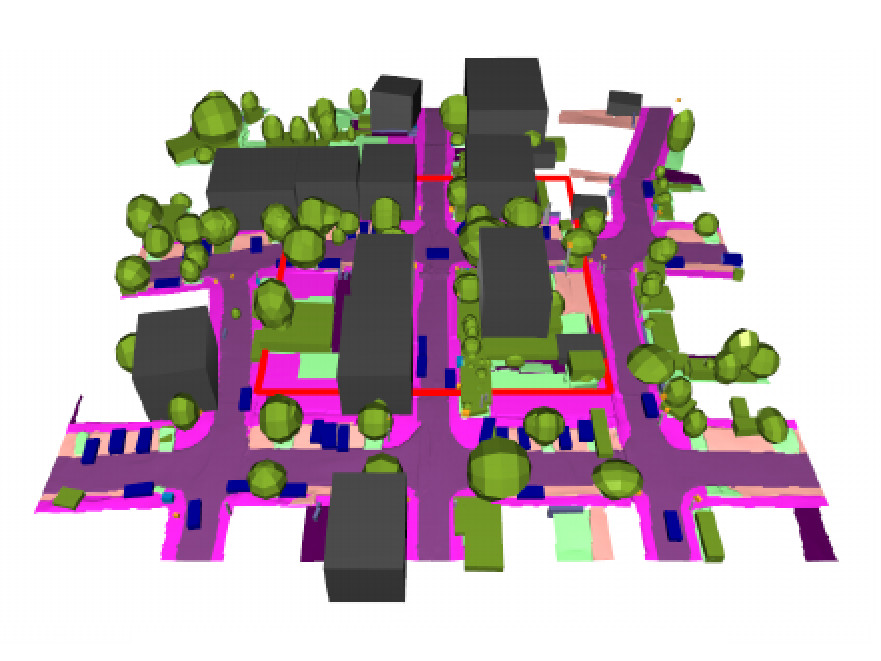
Autonomous vehicles must operate safely in the real world, where errors can have severe consequences. Although modern end-to-end driving policies excel in routine scenarios, their reliability is limited by the scarcity of safety-critical "long-tail" events in real driving datasets. These rare interactions define the practical safety boundary of the learned policy, yet they are difficult to collect at scale in the real world. Here we show that this fundamental limitation can be addressed by post-training pre-trained driving models on synthesized high-stakes interactions. We introduce World Engine, a generative framework that reconstructs high-fidelity interactive environments from real-world logs and systematically extrapolates them into realistic safety-critical variations. This paradigm enables reinforcement-based post-training to align policies with safety constraints, circumventing the physical risks inherent in real-world exploration. On a public benchmark built on nuPlan, World Engine substantially reduces failures in rare safety-critical scenarios and yields significantly larger gains than scaling pre-training data alone. Furthermore, when deployed on a production-scale autonomous driving system, the resulting policy reduces simulated collisions and demonstrates measurable improvements in on-road testing, showing that post-training on synthesized, safety-critical interactions offers a scalable and effective pathway to safer autonomous driving. The full codebase suite, including training, is released to the public.
@article{Li2026WorldEngine,
title = {World Engine: Towards the Era of Post-Training for Autonomous Driving},
author = {Tianyu Li and Li Chen and Caojun Wang and Haochen Liu and Kashyap Chitta and Zhenjie Yang and Yuhang Lu and Naisheng Ye and Yihang Qiu and Yufei Wang and Luoxi Zou and Jiaxin Peng and Jin Pan and Zhaoyu Su and Andrei Bursuc and Shengbo Eben Li and Andreas Geiger and Peng Su and Hongyang Li},
journal = {arXiv preprint arXiv:2606.19836},
year = {2026},
abstract = {Autonomous vehicles must operate safely in the real world, where errors can have severe consequences. Although modern end-to-end driving policies excel in routine scenarios, their reliability is limited by the scarcity of safety-critical "long-tail" events in real driving datasets. These rare interactions define the practical safety boundary of the learned policy, yet they are difficult to collect at scale in the real world. Here we show that this fundamental limitation can be addressed by post-training pre-trained driving models on synthesized high-stakes interactions. We introduce World Engine, a generative framework that reconstructs high-fidelity interactive environments from real-world logs and systematically extrapolates them into realistic safety-critical variations. This paradigm enables reinforcement-based post-training to align policies with safety constraints, circumventing the physical risks inherent in real-world exploration. On a public benchmark built on nuPlan, World Engine substantially reduces failures in rare safety-critical scenarios and yields significantly larger gains than scaling pre-training data alone. Furthermore, when deployed on a production-scale autonomous driving system, the resulting policy reduces simulated collisions and demonstrates measurable improvements in on-road testing, showing that post-training on synthesized, safety-critical interactions offers a scalable and effective pathway to safer autonomous driving. The full codebase suite, including training, is released to the public.}
}